R
Εισαγωγη στην R
Συναρτήσεις-Δομές ελέγχου ροής-Εισαγωγή, Τακτοποίηση & Αποθήκευση δεδομένων
Άννα Μοσχά Κέντρο Η/Υ, Ε.Μ.Π.
Περιεχομενα
- Συναρτήσεις
- Δομές ελέγχου ροής
- Δομές ροής: for loop
- Δομές ροής: while loop
- Δομές ροής: if else
- Συνάρτηση ifelse()
- Συνάρτησεις lapply(), sapply(), apply(), tapply()
- Παράδειγμα για lapply(), sapply()
- Παράδειγμα για tapply()
- Παραδείγματα για την tapply() από dataframes
- Παραδείγματα για την apply() από dataframes
- Εύρεση ύπαρξης Missing Values
- Script Files
- Εισαγωγή δεδομένων
- Τακτοποίηση-Καθαρισμός δεδομένων
- Τακτοποίηση-Καθαρισμός δεδομένων - Παράδειγμα
- Παράδειγμα χειρισμού των δεδομένων
- Recode μιας μεταβλητής σε πλαίσιο δεδομένων
- Παρατήρηση:Τρόποι πρόσθεσης μιας μεταβλητής σε dataframe
- Αποθήκευση αντικειμένων δεδομένων
Συναρτήσεις (1)
- Οι συναρτήσεις είναι κι αυτές αντικείμενα στην R
- Έχουν την μορφή: function ( λίστα με ορίσματα ) { εντολές υπολογισμού return ( τιμή ) }
- Η return μπορεί να παραλειφθεί. Όταν δεν αναφέρεται return η συνάρτηση επιστρέφει την τελευταία τιμή που υπολογίστηκε.
Συναρτήσεις (2)
- Παράδειγμα 1
> CircleArea <- function(radius) {
+ radius*radius*pi
+ }
> CircleArea(10)
[1] 314.1593
> CircleArea
function(radius) {
radius*radius*pi
}
> CircleArea()
Error in CircleArea() : argument "radius" is missing, with no default Συναρτήσεις (3)
-
Παρατηρήστε ότι μπορώ να δώσω ως όρισμα ένα διάνυσμα και να πάρω αποτέλεσμα διάνυσμα
> a=c(1,2,3,4,5)
> CircleArea(a)
[1] 3.141593 12.566371 28.274334 50.265482 78.539816
> plot(a, CircleArea(a)) # Σχεδιάζει απλό διάγραμμαΣυναρτήσεις (4)
- Παράδειγμα 2 : Συνάρτηση που διαβάζει χαρακτήρες και τυπώνει τους χαρακτήρες που διάβασε
> sayhello <- function(){
+ print("What's your name?")
+ y<-scan(what=character())
+ print(paste("Hello", y, sep=" "))}
> sayhello()
[1] "What's your name?"
1: Anna
2:
Read 1 item
[1] "Hello Anna"Δομές ελέγχου ροής(1)
- Οι δομές ελέγχου στην R επιτρέπουν τον έλεγχο στην ροή εκτέλεσης ενός προγράμματος με βάση κάποιων runtime συνθηκών.
- Οι συνηθισμένες δομές ελέγχου ροής είναι:
- for : εκτελεί μία επανάληψη (loop) για ένα σταθερό αριθμό φορών
- while : εκτελεί μία επανάληψη (loop) όσο μια συνθήκη είναι αληθής
- if, else : ελέγχει μια συνθήκη
Δομές ελέγχου ροής(2)
- Οι περισσότερες δομές ελέγχου δεν χρησιμοποιούνται στα αλληλεπιδραστικά sessions, αλλά όταν γράφουμε συναρτήσεις ή προγράμματα.
- Για command-line αλληλεπιδραστική εργασία χρησιμοποιείται η οικογένεια συναρτήσεων apply().
Δομές ροής: for loop (1)
- Τα for loops διαθέτουν μια μεταβλητή που μετρά τις επαναλήψεις στην οποία δίνονται διαδοχικές τιμές από μια ακολουθία ή ένα διάνυσμα.
- Έχουν την μορφή: for ( μεταβλητή in ακολουθία ) { εντολές προς εκτέλεση }
- Παράδειγμα 1: Για κάθε αριθμό από 1 έως το 5 τυπώνει το τετράγωνο του αριθμού.
> for (i in 1:5) print(i^2)
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25Δομές ροής: for loop (2)
- Παράδειγμα για αποφυγή for loop: Αντικαθιστά κάθε αρνητικό αριθμό του διανύσματος y με το μηδέν
> y<-c(-3,5,-5,20,-12,25,0)
> for (i in 1:length(y)) { if(y[i] < 0) y[i] <- 0 }
> y
[1] 0 5 0 20 0 25 0 > y<-c(-3,5,-5,20,-12,25,0)
> y [y < 0] <- 0
> y
[1] 0 5 0 20 0 25 0Δομές ροής: while loop
- Τα while loops ξεκινούν με τον έλεγχο μιας συνθήκης. Αν είναι αληθής, εκτελούν τις υπόλοιπες εντολές που περικλύονται μέσα στο loop. Μετά την πρώτη εκτέλεση των εντολών του loop η συνθήκη ελέγχεται ξανά κ.ο.κ.
- Έχουν την μορφή: while ( συνθήκη ) { εντολές προς εκτέλεση }
- Παράδειγμα: (Τα while loops αν δεν χρησιμοποιηθούν σωστά μπορεί να οδηγήσουν σε ατέρμονο βρόγχο. Χρειάζονται προσοχή.)
> count <- 0
> while(count < 5) {
+ print(count)
+ count <- count + 1
+ }
[1] 0
[1] 1
[1] 2
[1] 3
[1] 4 Δομές ροής: if else
- Έλεγχος συνθήκης με if else
if (expr_1) expr_2 else expr_3 - ή πιο αναλυτικά:
if(<condition>) {
## do something
} else {
## do something else
}
if(<condition1>) {
## do something
} else if(<condition2>) {
## do something different
} else {
## do something different
} Συνάρτηση ifelse() (1)
- Στην περίπτωση που θέλουμε, αν μια συνθήκη είναι αληθής, να κάνουμε μία Α πράξη ενώ αν είναι ψευδής, να κάνουμε μία διαφορετική πράξη, η συνάρτηση ifelse μας επιτρέπει να το κάνουμε αυτό σε ένα ολόκληρο διάνυσμα χωρίς την χρήση του for loop.
- Παράδειγμα 1: Αντικαθιστά τους αρνητικούς αριθμούς ενός διανύσματος y με το -1 και τους θετικούς με το 1
> y<-c(-3,5,-5,20,-12,25,0)
> z <- ifelse (y < 0, -1, 1)
> z
[1] -1 1 -1 1 -1 1 1Συνάρτηση ifelse() (2)
- Παράδειγμα 2: Αντικαθιστά τους αρνητικούς αριθμούς ενός διανύσματος y με τους αντίθετους τους ενώ τους θετικούς τους αφήνει ως έχουν.
> y<-c(-3,5,-5,20,-12,25,0)
> k <- ifelse (y < 0, -y, y)
> k
[1] 3 5 5 20 12 25 0 Συνάρτησεις lapply(), sapply(), apply(), tapply() (1)
- Τα for και while loops είναι χρήσιμα όταν προγραμματίζεις αλλά δεν είναι εύκολη διαδικασία όταν δουλεύεις αλληλεπιδραστικά σε command line περιβάλλον.
- Υπάρχει η οικογένεια συναρτήσεων apply() που δημιουργούν loops με εύκολο τρόπο.
- Οι συναρτήσεις που χρησιμοποιούνται περισσότερο είναι: lapply(), sapply(), apply(), tapply().
Συνάρτησεις lapply(), sapply(), apply(), tapply() (2)
- lapply(): Εφαρμόζει μία δεδομένη συνάρτηση σε κάθε στοιχείο μιας λίστας και παίρνει ως αποτέλεσμα μια λίστα.
- sapply(): Εφαρμόζει μία δεδομένη συνάρτηση σε κάθε στοιχείο μιας λίστας αλλά παίρνει ως αποτέλεσμα αντί για λίστα ένα διάνυσμα δηλαδή απλοποιεί το αποτέλεσμα.
- apply(): Εφαρμόζει μία δεδομένη συνάρτηση σε κάθε στοιχείο των γραμμών ( δείκτης 1) ή των στηλών (δείκτης 2) ενός πίνακα.
- tapply(): Εφαρμόζει μία δεδομένη συνάρτηση πάνω σε υποσύνολα ενός διανύσματος.
Συνάρτησεις lapply(), sapply(), apply(), tapply() (3)
- Πρέπει να σημειωθεί ότι η εφαρμογή αυτών των συναρτήσεων δεν οδηγεί αναγκαστικά και σε γρηγορότερη εκτέλεση (οι διαφορές δεν είναι τεράστιες).
- Η εφαρμογή των συναρτήσεων αυτών ενδείκνυται για την εκφραστικότητα τους.
- Η εφαρμογή τους οδηγεί σε αποφυγή των δυσκίνητων βρόχων μειώνοντας την πιθανότητα σφαλμάτων.
Παράδειγμα για lapply(), sapply() (1)
- Δημιουργώ μια λίστα με δύο όρους, ένα διάνυσμα από την ακολουθία αριθμών από το 1 έως το 5 και ένα διάνυσμα από 7 τυχαίους αριθμούς που ακολουθούν κανονική κατανομή με μέση τιμή 0 και τυπική απόκλιση 1.
> x <- list(a = 1:5, b = rnorm(7))
> x
$a
[1] 1 2 3 4 5
$b
[1] -1.4970726 1.2392563 0.0376222 -1.0396169 0.1536675 -1.0476383 0.7007813 Παράδειγμα για lapply(), sapply() (2)
- Χρησιμοποιώντας την lapply(x, mean) και sapply(x, mean) παίρνω την μέση τιμή κάθε στοιχείου της λίστας. Το αποτέλεσμα είναι αντίστοιχα λίστα ή διάνυσμα
> lapply(x, mean)
$a
[1] 3
$b
[1] -0.2075715
> sapply(x, mean)
a b
3.0000000 -0.2075715 Παράδειγμα για tapply() (1)
- Δημιουργώ διάνυσμα με 30 τυχαίους αριθμούς από τους οποίους οι 10 πρώτοι ακολουθούν κανονική κατανομή με μέση τιμή 0 και τυπική απόκλιση 1, οι επόμενοι 10 ομοιόμορφη κατανομή με min=0 και max=1 ( από την συνάρτηση runif(n, min = 0, max = 1) ) και οι τελευταίοι 10 κανονική κατανομή με μέση τιμή 1 και τυπική απόκλιση 1.
Παρατηρούμε ότι το διάνυσμα περιέχει 3 ομάδες - υποσύνολα. Εγώ θέλω την μέση τιμή κάθε μίας ομάδας του διανύσματος ξεχωριστά.> x <- c(rnorm(10), runif(10), rnorm(10, 1)) > x [1] -0.7153926 -0.1629948 -0.3993989 -0.5818607 0.2353145 1.0336660 0.4376461 [8] 1.3929560 -0.8899093 1.3994929 0.6027795 0.7252116 0.1695369 0.2199983 [15] 0.7804880 0.5629266 0.9183624 0.8898196 0.4162223 0.2931080 0.4652940 [22] 1.6527642 1.4594740 2.2958663 0.2243324 -0.6386001 1.4165570 1.0988965 [29] 2.0528085 1.2376103
Παράδειγμα για tapply() (2)
- Για να πάρω την μέση τιμή κάθε μίας ομάδας του διανύσματος ξεχωριστά δημιουργώ μία factor μεταβλητή με την συνάρτηση gl() που περιέχει 3 επίπεδα και το κάθε επίπεδο επαναλαμβάνεται 10 φορές έτσι ώστε να αντιστοιχίζει κάθε στοιχείο του διανύσματος x στην ομάδα του.
> f <- gl(3, 10)
> f
[1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3
Levels: 1 2 3 Παράδειγμα για tapply() (3)
- Εφαρμόζοντας τώρα την συνάρτηση mean μέσω της tapply() για το διάνυσμα x, το οποίο χωρίζεται μέσω της factor μεταβλητής f σε 3 ομάδες έχω την μέση τιμή για κάθε ομάδα σε απλοποιημένη μορφή by default.
> tapply(x, f, mean)
1 2 3
0.1749519 0.5578453 1.1265003 > tapply(x, rep(1:3, each=10), mean)
1 2 3
0.1749519 0.5578453 1.1265003
Παράδειγμα για tapply() (4)
- Αν χρησιμοποιήσω την συνάρτηση range() δεν θα έχω το αποτέλεσμα σε απλοποιημένη μορφή αλλά σε μορφή λίστας γιατί για κάθε ομάδα έχω ως αποτέλεσμα ένα διάνυσμα με 2 στοιχεία (min και max):
> tapply(x, f, range)
$`1`
[1] -0.8899093 1.3994929
$`2`
[1] 0.1695369 0.9183624
$`3`
[1] -0.6386001 2.2958663Παραδείγματα για την tapply() από dataframes (1)
- Θα θυμηθούμε το dataframe total:
> total
id sex height smoking weight
1 Marc Male 180 TRUE 80
2 Mary Female 160 FALSE 60
3 Kelly Female 167 FALSE 65
4 George Male 175 TRUE 100
5 Peter Male 190 FALSE 85
6 John Male 195 FALSE 95 > tapply(total$height, total$sex, mean)
Female Male
163.5 185.0Παραδείγματα για την tapply() από dataframes (1)
- Για να πάρουμε τo μέσο βάρος αυτών που καπνίζουν και αυτών που δεν καπνίζουν (δηλ. ανά ομάδα που χωρίζεται από την μεταβλητή smoking)
> tapply(total$w, total$smoking, mean)
FALSE TRUE
76.25 90.00 > tapply(total$h, total$smoking, max)
FALSE TRUE
195 180 Παραδείγματα για την apply() από dataframes (2)
- Για να πάρουμε την μέση τιμή για την μεταβλητή ύψος και την μεταβλητή βάρος
> c(mean(total$h), mean(total$w))
[1] 177.83333 80.83333> apply(total[,c(3,5)],2,mean)
height weight
177.83333 80.83333 > apply(total[,c("height", "weight")],2,mean)
height weight
177.83333 80.83333 Εύρεση ύπαρξης Missing Values (1)
- Χρησιμοποιώντας την συνάρτηση is.na().
Παράδειγμα:
> a<-c(1,2,3,4,NA,NA)
> is.na(a)
[1] FALSE FALSE FALSE FALSE TRUE TRUE
> sum(is.na(a))
[1] 2 Εύρεση ύπαρξης Missing Values (2)
- Χρησιμοποιώντας την συνάρτηση complete.cases().
Παράδειγμα:
> a<-c(1,2,3,4,NA,NA)
> complete.cases(a)
[1] TRUE TRUE TRUE TRUE FALSE FALSE
> sum(complete.cases(a))
[1] 4
> length(a)
[1] 6Εύρεση ύπαρξης Missing Values (3)
- Χρησιμοποιώντας τον συνδυασμό which(is.na()) για να πάρω ακριβώς την θέση των Missing Values.
Παράδειγμα:
> a<-c(1,2,3,4,NA,NA)
> which(is.na(a))
[1] 5 6Script Files (1)
- Τα script files έχουν κατάληξη .r , είναι text αρχεία και περιέχουν κώδικα
- Όταν κατά την ανάλυση των δεδομένων μια διαδικασία επαναλαμβάνεται, καλό είναι να τη γράφουμε σε ένα script file για να μην την πληκτρολογούμε συνέχεια στην κονσόλα την ίδια.
- Παράδειγμα: Γράφω στον script editor:
myfunction<-function(){
x=rnorm(100)
mean(x)
} Script Files (2)
- Για να δω το αρχείο myfirstcode.r στην κονσόλα χρησιμοποιώ την dir()
> dir()
[1] "a.R"
[2] "complete.R"
.....................................................
[17] "myfirstcode.r"
[18] "mygradesmm2014.txt"
......................................................
[30] "x.txt" Script Files (3)
- Για να χρησιμοποιήσω τον κώδικά του script file θα πρέπει πρώτα να φορτώσω και να εκτελέσω το συγκεκριμένο script χρησιμοποιώντας την source()
> myfunction()
Error: could not find function "myfunction"
> source("myfirstcode.r")
> myfunction()
[1] 0.1123094
> myfunction
function(){
x=rnorm(100)
mean(x)
}Εισαγωγή δεδομένων(1)
- Εισαγωγή δεδομένων (data frames) με τις εντολές:
- read.table() : διαβάζει ένα αρχείο που είναι σε μορφή πίνακα και δημιουργεί ένα dataframe
- read.csv(): διαβάζει ένα csv αρχείο που είναι σε μορφή πίνακα και δημιουργεί ένα dataframe
- read.fwf(): διαβάζει πίνακα με fixed width format data και δημιουργεί ένα dataframe
Εισαγωγή δεδομένων(2)
- Παραδείγματα:
> z<-read.table(file="mmgrades2014.csv",header=T, sep=",")
> z
ID_number Sex X.Course_total Technical_English EAP Exam Final_mark
1 mm12023 M 65.80 2.0 1 4.0 7
2 mm12038 M 77.67 2.0 0 3.6 6
3 mm12054 M 86.75 2.0 0 2.5 2
.......................................................................> x<-read.table("clipboard",header=T, sep=",")
> x
ID_number Sex X.Course_total Technical_English EAP Exam Final_mark
1 mm12023 M 65.80 2.0 1 4.0 7
2 mm12038 M 77.67 2.0 0 3.6 6
3 mm12054 M 86.75 2.0 0 2.5 2
...................................................................... Εισαγωγή δεδομένων(3)
- Παραδείγματα:
> f<-read.table("clipboard", header=T, sep="")
Error in scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings,
line 14 did not have 7 elements
> f<-read.table("clipboard", header=T,sep="",fill=T)
> f
ID number Sex Course total Technical English EAP
1 mm12023 M 65.80 % 2.0 1 4.0 7
2 mm12038 M 77.67 % 2.0 0 3.6 6
3 mm12054 M 86.75 % 2.0 0 2.5 2
........................................................... > t<-read.csv(file="mmgrades2014.csv", header=T, sep=",")
> t
ID_number Sex X.Course_total Technical_English EAP Exam Final_mark
1 mm12023 M 65.80 2.0 1 4.0 7
2 mm12038 M 77.67 2.0 0 3.6 6
.......................................................................Εισαγωγή δεδομένων(4)
- Παραδείγματα:
> names(z)
[1] "ID_number" "Sex" "X.Course_total" "Technical_English"
[5] "EAP" "Exam" "Final_mark" > names(z)[3]<-"Course_total_%"
> str(z)
'data.frame': 47 obs. of 7 variables:
$ ID_number : Factor w/ 47 levels "mm06060","mm07041",..: 21 28 38 47 27 6 37 30 13 22 ...
$ Sex : Factor w/ 2 levels "F","M": 2 2 2 1 1 1 1 1 2 1 ...
$ Course_total_% : num 65.8 77.67 86.75 3.33 84.13 ...
$ Technical_English: num 2 2 2 0 2 2 1.8 2 2 2 ...
$ EAP : int 1 0 0 0 1 0 0 0 0 0 ...
$ Exam : num 4 3.6 2.5 2.5 6.6 3.9 1.3 1 3.5 4.6 ...
$ Final_mark : int 7 6 2 2 10 6 2 1 6 7 ...Εισαγωγή δεδομένων(5)
- Παραδείγματα:
> z$ID_number<-as.character(z$ID_number)
> str(z)
'data.frame': 47 obs. of 7 variables:
$ ID_number : chr "mm12023" "mm12038" "mm12054" "mm12554" ...
$ Sex : Factor w/ 2 levels "F","M": 2 2 2 1 1 1 1 1 2 1 ...
$ Course_total_% : num 65.8 77.67 86.75 3.33 84.13 ...
$ Technical_English: num 2 2 2 0 2 2 1.8 2 2 2 ...
$ EAP : int 1 0 0 0 1 0 0 0 0 0 ...
$ Exam : num 4 3.6 2.5 2.5 6.6 3.9 1.3 1 3.5 4.6 ...
$ Final_mark : int 7 6 2 2 10 6 2 1 6 7 ... Τακτοποίηση-Καθαρισμός δεδομένων
- Πριν περάσει κανείς στην ανάλυση δεδομένων θα πρέπει τα δεδομένα να είναι σωστά τακτοποιημενα και καθαρά
- Πρέπει να γίνει τακτοποίηση δεδομένων (Tidy Data)
- Πρέπει να γίνει καθαρισμός δεδομένων (Clean Data)
- Συνήθως μπορεί να οδηγηθώ σε μετασχηματισμό των μεταβλητών (Recode)
Τακτοποίηση δεδομένων
- Tidy Data
- Κάθε γραμμή να είναι μία παρατήρηση π.χ. να είναι οι μετρήσεις ενός ανθρώπου
- Κάθε στήλη να είναι μία μεταβλητή π.χ. να είναι η ηλικία, όχι ηλικία και φύλο μαζί
Καθαρισμός δεδομένων
- Clean Data
- Καθαρισμός από πιθανά οφθαλμοφανή λάθη που έγιναν κατά την εισαγωγή δεδομένων
- Διόρθωση των τύπων των μεταβλητών
- Διόρθωση της μορφής των μεταβλητών
Τακτοποίηση-Καθαριμός δεδομένων - Παράδειγμα (1)
- Κατεβάζω το αρχείο με το όνομα "Obes-phys-acti-diet-eng-2014-tab_CSV.csv" από το site https://data.gov.uk/ στο working directory μου.
- Περιέχει στοιχεία για παχυσαρκία, φυσική άσκηση και δίαιτα.
- Το ανοίγω με έναν text editor και παρατηρώ τα δεδομένα
- Παρατηρώ ότι είναι συγκεντρωτικά δεδομένα.
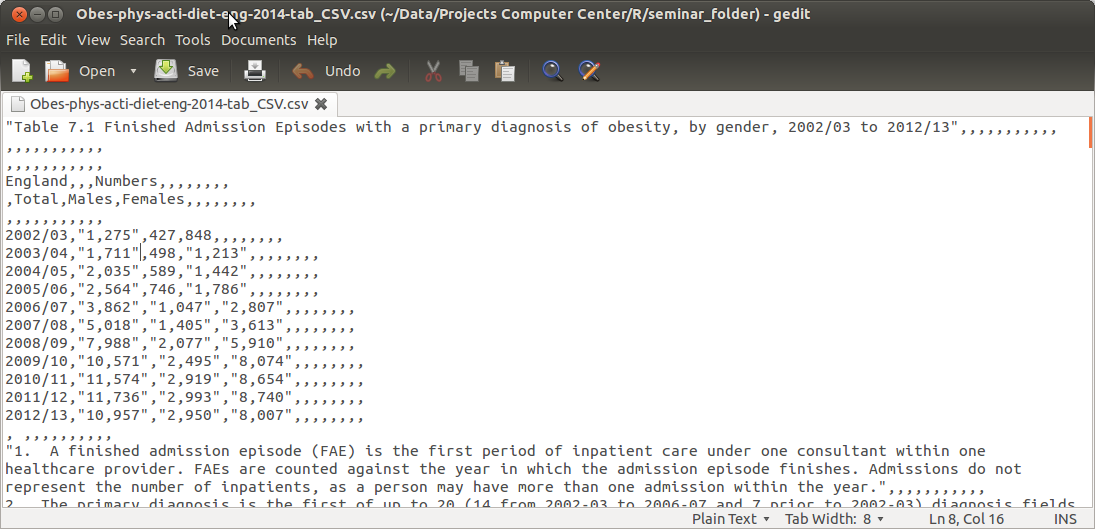
Τακτοποίηση-Καθαριμός δεδομένων - Παράδειγμα (2)
- Θα αποθηκεύσω στην μεταβλητή obesity ένα μικρό μέρος από τα δεδομένα του αρχείου.
> obesity<-read.csv("Obes-phys-acti-diet-eng-2014-tab_CSV.csv", skip=4, nrows=12)
> str(obesity)
'data.frame': 12 obs. of 12 variables:
$ X : Factor w/ 12 levels "","2002/03","2003/04",..: 1 2 3 4 5 6 7 8 9 10 ...
$ Total : Factor w/ 12 levels "","10,571","10,957",..: 1 6 7 8 9 10 11 12 2 4 ...
$ Males : Factor w/ 12 levels "","1,047","1,405",..: 1 9 10 11 12 2 3 4 5 6 ...
$ Females: Factor w/ 12 levels "","1,213","1,442",..: 1 10 2 3 4 5 6 7 9 11 ...
$ X.1 : logi NA NA NA NA NA NA ...
$ X.2 : logi NA NA NA NA NA NA ...
$ X.3 : logi NA NA NA NA NA NA ...
$ X.4 : logi NA NA NA NA NA NA ...
$ X.5 : logi NA NA NA NA NA NA ...
$ X.6 : logi NA NA NA NA NA NA ...
$ X.7 : logi NA NA NA NA NA NA ...
$ X.8 : logi NA NA NA NA NA NA ... Τακτοποίηση-Καθαριμός δεδομένων - Παράδειγμα (3)
- Τις μεταβλητές Total, Males και Females τις θεώρησε ως factors και όχι ως αριθμητικές γιατί οι αριθμοί περιέχουν το κόμμα.
- Για να εξαλείψω το κόμμα χρησιμοποιώ την συνάρτηση gsub()
> obesity$Males<- as.numeric(as.character(gsub(",","",obesity$Males)))
> obesity$Females<- as.numeric(as.character(gsub(",","",obesity$Females)))
> obesity
X Total Males Females X.1 X.2 X.3 X.4 X.5 X.6 X.7 X.8
1 NA NA NA NA NA NA NA NA NA NA
2 2002/03 1,275 427 848 NA NA NA NA NA NA NA NA
3 2003/04 1,711 498 1213 NA NA NA NA NA NA NA NA
4 2004/05 2,035 589 1442 NA NA NA NA NA NA NA NA
5 2005/06 2,564 746 1786 NA NA NA NA NA NA NA NA
..................................................................Τακτοποίηση-Καθαριμός δεδομένων - Παράδειγμα (4)
- Για να σβήσουμε τις επιπλέον γραμμές και στήλες που δεν χρειάζονται χρησιμοποιούμε το αρνητικό πρόσημο.
> obesity
X Total Males Females X.1 X.2 X.3 X.4 X.5 X.6 X.7 X.8
1 NA NA NA NA NA NA NA NA NA NA
2 2002/03 1,275 427 848 NA NA NA NA NA NA NA NA
3 2003/04 1,711 498 1213 NA NA NA NA NA NA NA NA
4 2004/05 2,035 589 1442 NA NA NA NA NA NA NA NA
5 2005/06 2,564 746 1786 NA NA NA NA NA NA NA NA
6 2006/07 3,862 1047 2807 NA NA NA NA NA NA NA NA
7 2007/08 5,018 1405 3613 NA NA NA NA NA NA NA NA
8 2008/09 7,988 2077 5910 NA NA NA NA NA NA NA NA
9 2009/10 10,571 2495 8074 NA NA NA NA NA NA NA NA
10 2010/11 11,574 2919 8654 NA NA NA NA NA NA NA NA
11 2011/12 11,736 2993 8740 NA NA NA NA NA NA NA NA
12 2012/13 10,957 2950 8007 NA NA NA NA NA NA NA NA
> obesity<-obesity[-1, c(-2,-5:-12)] Τακτοποίηση-Καθαριμός δεδομένων - Παράδειγμα (5)
- Έχουμε πλέον:
> obesity X Males Females 2 2002/03 427 848 3 2003/04 498 1213 4 2004/05 589 1442 5 2005/06 746 1786 6 2006/07 1047 2807 7 2007/08 1405 3613 8 2008/09 2077 5910 9 2009/10 2495 8074 10 2010/11 2919 8654 11 2011/12 2993 8740 12 2012/13 2950 8007 - Η παραπάνω μορφή δεδομένων λέγεται wide format. Κάθε γραμμή δεν περιέχει μία παρατήρηση, η μεταβλητή gender είναι μοιρασμένη σε δύο μεταβλητές Males και Females.
Τακτοποίηση-Καθαριμός δεδομένων - Παράδειγμα (6)
- Για να μετατρέψουμε τα δεδομένα σε long format δηλ. κάθε γραμμή να περιέχει μία παρατήρηση θα χρησιμοποιήσουμε την συνάρτηση melt() που περιέχεται στο πακέτο reshape2 το οποίο θα εγκαταστήσουμε.
> install.packages("reshape2") # εγκαθιστώ το πακέτο
Installing package into ‘/home/anna/R/x86_64-pc-linux-gnu-library/3.1’
(as ‘lib’ is unspecified)
.......................................................................
> library("reshape2") # ενεργοποιώ το πακέτο
> obesitylong<-melt(obesity)
Using X as id variables
> obesitylong
X variable value
1 2002/03 Males 427
2 2003/04 Males 498
3 2004/05 Males 589
4 2005/06 Males 746
5 2006/07 Males 1047
6 2007/08 Males 1405
7 2008/09 Males 2077
8 2009/10 Males 2495
9 2010/11 Males 2919
10 2011/12 Males 2993
11 2012/13 Males 2950
12 2002/03 Females 848
13 2003/04 Females 1213
14 2004/05 Females 1442
15 2005/06 Females 1786
16 2006/07 Females 2807
17 2007/08 Females 3613
18 2008/09 Females 5910
19 2009/10 Females 8074
20 2010/11 Females 8654
21 2011/12 Females 8740
22 2012/13 Females 8007 Τακτοποίηση-Καθαριμός δεδομένων - Παράδειγμα (7)
- Παρατηρήστε την διαφορά του long format με του wide format. Πολλές στατιστικές αναλύσεις στην R απαιτούν την long format.
| wide format : obesity | long format : obesitylong |
|---|---|
|
|
Παράδειγμα χειρισμού των δεδομένων (1)
- Από το data frame z θέλουμε να υπολογίσουμε πόσοι φοιτητές πήραν βαθμό πάνω από 6.8
> z
ID_number Sex Course_total_% Technical_English EAP Exam Final_mark
1 mm12023 M 65.80 2.0 1 4.0 7
2 mm12038 M 77.67 2.0 0 3.6 6
3 mm12054 M 86.75 2.0 0 2.5 2
4 mm12554 F 3.33 0.0 0 2.5 2
5 mm12035 F 84.13 2.0 1 6.6 10
6 mm11054 F 67.09 2.0 0 3.9 6
7 mm12053 F 68.64 1.8 0 1.3 2
8 mm12040 F 91.94 2.0 0 1.0 1
9 mm12011 M 86.83 2.0 0 3.5 6
10 mm12024 F 83.24 2.0 0 4.6 7
11 mm12044 F 86.98 2.0 1 4.6 8
12 mm12033 M 81.27 2.0 0 4.8 3
13 mm07041 F 74.90 2.0 0 1.5 2
14 mm12022 M 90.85 2.0 0 4.9 NA
15 mm12553 M 76.17 2.0 0 2.9 3
.......................................................................Παράδειγμα χειρισμού των δεδομένων (2)
- Από το data frame z θέλουμε να υπολογίσουμε πόσοι φοιτητές πήραν βαθμό πάνω από 6.8
> z$Final_mark[z$Final_mark>6.8]
[1] 7 10 7 8 NA 7 7 7 8 NA 10 8 7 7 9 7 7 8 7 8> length(z$Final_mark[z$Final_mark>6.8])
[1] 20> length(complete.cases(z$Final_mark[z$Final_mark>6.8]))
[1] 20 Παράδειγμα χειρισμού των δεδομένων (3)
- Από το data frame z θέλουμε να υπολογίσουμε πόσοι φοιτητές πήραν βαθμό πάνω από 6.8
> complete.cases(z$Final_mark[z$Final_mark>6.8])
[1] TRUE TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUE FALSE TRUE TRUE TRUE
[14] TRUE TRUE TRUE TRUE TRUE TRUE TRUE> sum(complete.cases(z$Final_mark[z$Final_mark>6.8]))
[1] 18> sum(is.na(z$Final_mark[z$Final_mark>6.8]))
[1] 2Παράδειγμα χειρισμού των δεδομένων (4)
- Από το data frame z θέλουμε να υπολογίσουμε πόσοι φοιτητές πήραν βαθμό πάνω από 6.8
- 2ος τρόπος πιο άμεσος:
> z$Final>6.8
[1] TRUE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE NA
[15] FALSE TRUE FALSE TRUE TRUE FALSE FALSE TRUE FALSE FALSE FALSE NA TRUE TRUE
[29] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE
[43] FALSE FALSE TRUE TRUE FALSE
> sum(z$Final>6.8)
[1] NA
> sum(z$Final>6.8, na.rm=TRUE)
[1] 18Recode μιας μεταβλητής σε πλαίσιο δεδομένων (1)
- Έστω ότι θέλουμε να έχουμε την τελική βαθμολογία (Final_mark) των φοιτητών στο data frame z και σε κλίμακα A, B, C, D.
- Χρησιμοποιώ την συνάρτηση cut() για την μετατροπή μιας numeric μεταβλητής σε factor:
> cut(z$Final, breaks=c(1,5,7,9,10), include.lowest=TRUE, right=FALSE, ordered_result=TRUE )
[1] [7,9) [5,7) [1,5) [1,5) [9,10] [5,7) [1,5) [1,5) [5,7) [7,9) [7,9)
[12] [1,5) [1,5) [1,5) [7,9) [5,7) [7,9) [7,9) [1,5) [5,7) [7,9)
[23] [1,5) [1,5) [1,5) [9,10] [7,9) [1,5) [1,5) [1,5) [7,9) [5,7)
[34] [5,7) [1,5) [5,7) [5,7) [7,9) [9,10] [7,9) [7,9) [7,9) [1,5) [5,7)
[45] [7,9) [7,9) [5,7)
Levels: [1,5) < [5,7) < [7,9) < [9,10] Recode μιας μεταβλητής σε πλαίσιο δεδομένων (2)
- Έστω ότι θέλουμε να έχουμε την τελική βαθμολογία (Final_mark) των φοιτητών στο data frame z και σε κλίμακα A, B, C, D.
> Letter_Final_mark<-cut(z$Final, breaks=c(1,5,7,9,10),labels=c("D", "C", "B","A"),
include.lowest=TRUE, right=FALSE, ordered_result=TRUE )
> Letter_Final_mark
[1] B C D D A C D D C B B D D D B C
[18] B B D C B D D D A B D D D B C C
[35] D C C B A B B B D C B B C
Levels: D < C < B < A
> class(Letter_Final_mark)
[1] "ordered" "factor" Recode μιας μεταβλητής σε πλαίσιο δεδομένων (3)
- Έστω ότι θέλουμε να έχουμε την τελική βαθμολογία (Final_mark) των φοιτητών στο data frame z και σε κλίμακα A, B, C, D.
> z$Letter_Final_mark<-Letter_Final_mark
> z
ID_number Sex Course_total_% Technical_English EAP Exam Final_mark Letter_Final_mark
1 mm12023 M 65.80 2.0 1 4.0 7 B
2 mm12038 M 77.67 2.0 0 3.6 6 C
3 mm12054 M 86.75 2.0 0 2.5 2 D
4 mm12554 F 3.33 0.0 0 2.5 2 D
5 mm12035 F 84.13 2.0 1 6.6 10 A
6 mm11054 F 67.09 2.0 0 3.9 6 C
.........................................................................................Παρατήρηση:Τρόποι πρόσθεσης μιας μεταβλητής σε dataframe (1)
- Μπορώ να προσθέσω μια επιπλέον μεταβλητή (στήλη) βάζοντας όλες τις τιμές της NA και στη συνέχεια να αλλάξω τις τιμές της κατάλληλα.
> z$New1<-NA
> z
ID_number Sex Course_total_% Technical_English EAP Exam Final_mark Letter_Final_mark New1
1 mm12023 M 65.80 2.0 1 4.0 7 B NA
2 mm12038 M 77.67 2.0 0 3.6 6 C NA
3 mm12054 M 86.75 2.0 0 2.5 2 D NA
4 mm12554 F 3.33 0.0 0 2.5 2 D NA
.............................................................................................
> z<-z[-9] # Την σβήνω για να επανέλθω στην προηγούμενη κατάστασηΠαρατήρηση:Τρόποι πρόσθεσης μιας μεταβλητής σε dataframe (2)
- Μπορώ να κάνω την υπάρχουσα μεταβλητή Final_mark copy σε μια νέα μεταβλητή και στη συνέχεια να αλλάξω τις τιμές της.
> z$New2<-z$Final_mark
> z
ID_number Sex Course_total_% Technical_English EAP Exam Final_mark Letter_Final_mark New2
1 mm12023 M 65.80 2.0 1 4.0 7 B 7
2 mm12038 M 77.67 2.0 0 3.6 6 C 6
3 mm12054 M 86.75 2.0 0 2.5 2 D 2
4 mm12554 F 3.33 0.0 0 2.5 2 D 2
..............................................................................................
> z<-z[-9] # Την σβήνω για να επανέλθω στην προηγούμενη κατάστασηΑποθήκευση αντικειμένων δεδομένων (1)
- Αποθήκευση διανύσματος με την write()
> t<-c(1,2,3,4,5)
> write(t, "t.txt")Αποθήκευση αντικειμένων δεδομένων (2)
- Αποθήκευση πίνακα με την write()
> m <- matrix(1:10, ncol = 5)
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> write(m, "m.txt")
> scan("m.txt")
Read 10 items
[1] 1 2 3 4 5 6 7 8 9 10
> j<-matrix(scan("m.txt"), ncol=5)
Read 10 items
> j
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10Αποθήκευση αντικειμένων δεδομένων (3)
- Αποθήκευση data frame με την write.table()
> write.table(z, "mygradesmm2014.txt")
> read.table("mygradesmm2014.txt")
ID_number Sex Course_total_. Technical_English EAP Exam Final_mark Letter_Final_mark
1 mm12023 M 65.80 2.0 1 4.0 7 B
2 mm12038 M 77.67 2.0 0 3.6 6 C
3 mm12054 M 86.75 2.0 0 2.5 2 D
4 mm12554 F 3.33 0.0 0 2.5 2 D
........................................................................................Αποθήκευση αντικειμένων δεδομένων (4)
- Αποθήκευση data frame με την write.csv()
> write.csv(z, "mygradesmm2014.csv")
> read.csv("mygradesmm2014.csv")
X ID_number Sex Course_total_. Technical_English EAP Exam Final_mark Letter_Final_mark
1 1 mm12023 M 65.80 2.0 1 4.0 7 B
2 2 mm12038 M 77.67 2.0 0 3.6 6 C
3 3 mm12054 M 86.75 2.0 0 2.5 2 D
4 4 mm12554 F 3.33 0.0 0 2.5 2 D
.........................................................................
> write.csv(z, "mygradesmm2014.csv", row.names=FALSE)
> read.csv("mygradesmm2014.csv")
ID_number Sex Course_total_. Technical_English EAP Exam Final_mark Letter_Final_mark
1 mm12023 M 65.80 2.0 1 4.0 7 B
2 mm12038 M 77.67 2.0 0 3.6 6 C
3 mm12054 M 86.75 2.0 0 2.5 2 D
4 mm12554 F 3.33 0.0 0 2.5 2 D
.......................................................................................