Περιεχομενα
- Σκοπός της Περιγραφικής Στατιστικής
- Μέθοδοι της Περιγραφικής Στατιστικής
- Τύποι Μεταβλητών ως προς την κλίμακα μέτρησης
- Τύποι Μεταβλητών - Δεδομένα (συγκεντρωτικά)
- Παραδείγματα δεδομένων στην R
- Αριθμητικές Μέθοδοι - Ποσοτικές Μεταβλητές
- Αριθμητικές Μέθοδοι - Κατηγορικές Μεταβλητές
- Γραφικές Μέθοδοι στην R
- Γραφ. Μέθοδοι- Ποσοτικές μεταβλητές
- Γραφ. Μέθοδοι- Κατηγορικές μεταβλητές
- Γραφ. Μέθοδοι - Η συνάρτηση plot()
Σκοπός της Περιγραφικής Στατιστικής
- Σκοπός της Περιγραφικής Στατιστικής είναι:
- να οργανώσει
- να παρουσιάσει συνοπτικά τα δεδομένα
- να ελέγξει την ορθότητα των δεδομένων (π.χ. εμφάνιση ακραίων τιμών-outliers ή missing values-στην R συμβολίζονται με NA).
Μέθοδοι της Περιγραφικής Στατιστικής
- Οι μέθοδοι που χρησιμοποιεί η Περιγραφική Στατιστική είναι:
- Αριθμητικές:
- Υπολογισμός μέτρων Θέσης (Γύρω από ποια τιμή κινείται το πλήθος των παρατηρήσεων)
- Υπολογισμός μέτρων Μεταβλητότητας (Πόσο διαφέρουν οι παρατηρήσεις μεταξύ τους).
- Γραφικές:
Ο τύπος της μεταβλητής που θέλω να μελετήσω καθορίζει την κατάλληλη αριθμητική και γραφική μέθοδο που θα επιλέξω
Τύποι Μεταβλητών ως προς την κλίμακα μέτρησης (1)
- Ποιοτική ή Κατηγορική:
Η μεταβλητή που μεταβάλεται σε είδος. Εκφράζει καταστάσεις, π.χ. η φύση του υλικού
- Ποσοτική:
Η μεταβλητή που μεταβάλεται σε ποσό. Εκφράζει ποσότητα, π.χ. το βάρος ενός υλικού
Τύποι Μεταβλητών ως προς την κλίμακα μέτρησης (2)
- Η Ποιοτική χωρίζεται σε:
- Ονομαστική (nominal):
Η μεταβλητή που δεν επιδέχεται καμία κατάταξη (π.χ. η φύση του υλικού)
- Διάταξης (ordinal):
Η μεταβλητή που επιτρέπει ιεράρχηση - διάταξη (π.χ. ποιοτική διαβάθμιση προϊόντος)
Τύποι Μεταβλητών ως προς την κλίμακα μέτρησης (3)
- Η Ποσοτική χωρίζεται σε:
- Διαστήματος (interval):
Η μεταβλητή που επιτρέπει την ιεράρχηση και επιπλέον την μέτρηση της διαφοράς των τιμών της. Δεν υπάρχει η έννοια του απόλυτου μηδέν. (π.χ. η θερμοκρασία)
- Αναλογική (ratio):
Η μεταβλητή που επιτρέπει την ιεράρχηση και την μέτρηση της διαφοράς των τιμών της αλλά επιπλέον έχει νόημα η αναλογία των τιμών της αφού υπάρχει η έννοια του απόλυτου μηδέν. (π.χ. βάρος υλικού)
Τύποι Μεταβλητών ως προς την κλίμακα μέτρησης (4)
- Επίσης η Ποσοτική χωρίζεται και σε:
- Διακριτή:
Η μεταβλητή που παίρνει τιμές από κάποιο πεπερασμένο σύνολο διακριτών αριθμών ή από κάποιο άπειρο αλλά αριθμήσιμο σύνολο. (π.χ. αριθμός εξαρτημάτων μιας μηχανής)
- Συνεχής:
Η μεταβλητή που το σύνολο των τιμών της μπορεί να είναι οποιοσδήποτε αριθμός από ένα συνεχές διάστημα (π.χ. διάρκεια ζωής ενός εξαρτήματος)
Τύποι Μεταβλητών - Δεδομένα (συγκεντρωτικά)
![Είδη Μεταβλητών]()
Παραδείγματα δεδομένων στην R (1)
- Στη βασική εγκατάσταση της R γίνεται αυτόματη εγκατάσταση του πακέτου "datasets" που περιέχει δεδομένα που δίνονται για εξάσκηση με την R
- Με την συνάρτηση data() βλέπουμε λίστα με τα διαθέσιμα data sets (στο script window του RStudio ή στην κονσόλα αν τρέχουμε την R χωρίς το RStudio) ή μπορούμε να φορτώσουμε συγκεκριμένο data set
> data()
> data(cars)
> ?cars
Παρατηρήστε ότι με ? και το όνομα του data set παίρνουμε πληροφορίες για το συγκεκριμένο data set στην καρτέλα Ηelp
Παραδείγματα δεδομένων στην R (2)
- Παράδειγμα του data set cars
> str(cars)
'data.frame': 50 obs. of 2 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...
> head(cars)
speed dist
1 4 2
2 4 10
3 7 4
4 7 22
5 8 16
6 9 10
Παρατηρήστε ότι το dataset cars περιλαμβάνει 2 ποσοτικές μεταβλητές
Αρ. Μέθοδοι-Ποσοτικές Μεταβλητές
- Μέτρα θέσης: Γύρω από ποια τιμή κινούνται το πλήθος των παρατηρήσεων (το κέντρο των παρατηρήσεων)
- Μέση τιμή : \[ \overline{x}=\frac{1}{n}\displaystyle\sum_{i=1}^{n} x_i \]
Επηρεάζεται από τις ακραίες τιμές. Παίρνουμε την μέση τιμή μεταβλητής στην R με την συνάρτηση mean(). Παράδειγμα:
> mean(cars$speed)
[1] 15.4
Αρ. Μέθοδοι-Ποσοτικές Μετ.
- Μέτρα θέσης (συνέχεια):
- Διάμεσος : Η μεσαία παρατήρηση αφού διαταχθούν οι παρατηρήσεις του δείγματος. Δεν επηρεάζεται από τις ακραίες τιμές. Παίρνουμε την διάμεσο μεταβλητής στην R με την συνάρτηση median(). Παράδειγμα:
> median(cars$speed)
[1] 15
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Μέτρα θέσης (συνέχεια):
- Επικρατούσα τιμή (Δειγματική κορυφή) : Η παρατήρηση με την μεγαλύτερη συχνότητα (έχει νόημα στις διακριτές μεταβλητές). Στην R για να πάρω την επικρατούσα τιμή έχω:
> t<- table(cars$speed)
> t
4 7 8 9 10 11 12 13 14 15 16 17 18 19 20 22 23 24 25
2 2 1 1 3 2 4 4 4 3 2 3 4 3 5 1 1 4 1
> t[t==max(t)]
20
5
Παρατηρήστε ότι η συνάρτηση table() δίνει σε πίνακα τις διαφορετικές τιμές της μεταβλητής με την αντίστοιχη συχνότητα τους. Στο συγκεκριμένο παράδειγμα η ταχύτητα που εμφανίζεται περισσότερες φορές στο δείγμα είναι η 20 η οποία εμφανίζεται 5 φορές.
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Αν υπάρχουν NA στα δεδομένα οι προηγούμενες συναρτήσεις δίνουν NA ως αποτέλεσμα. Θα πρέπει να βάλουμε na.rm=TRUE.
Παράδειγμα:
> x<-c(1,2,3,4,5,6,NA,8,9,10,NA,11)
> mean(x)
[1] NA
> mean(x, na.rm=T)
[1] 5.9
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Μέτρα Μεταβλητότητας: Πόσο διάσπαρτες είναι οι παρατηρήσεις
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Μέτρα Μεταβλητότητας (συνέχεια) :
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Μέτρα Μεταβλητότητας (συνέχεια) :
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Μέτρα Μεταβλητότητας (συνέχεια) :
- Ενδοτεταρτομοριακό Εύρος (Interquartile Range - IQR): η διαφορά του 3ου από το 1ο τεταρτημόριο. Το 1ο και το 3ο τεταρτημόριο είναι η παρατήρηση εκείνη που είναι μεγαλύτερη ή ίση από το 25% (και το 75% αντίστοιχα) ακριβώς όλων των παρατηρήσεων. Δεν επηρεάζεται από τις ακραίες τιμές.
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Μέτρα Μεταβλητότητας (συνέχεια) :
- Ενδοτεταρτομοριακό Εύρος (συνέχεια) : Στην R το 1ο και 3ο τεταρτημόριο τα παίρνουμε με την συνάρτηση quantile(x, p) όπου p=0.25 και p=0.75 αντίστοιχα.
Παράδειγμα:
> quantile(cars$speed, .25)
25%
12
> quantile(cars$speed, 0.75)
75%
19
> quantile(cars$speed, 0.5)
50%
15
Παρατηρήστε ότι αν στην συνάρτηση quantile() θέσουμε p=0.5 έχουμε τη διάμεσο.
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Μέτρα Μεταβλητότητας (συνέχεια) :
- Συντελεστής μεταβλητότητας (Coefficient of Variation) : \[ CV=\frac{s} {\overline{x}} \]
- Είναι ένα μέτρο σχετικής διασποράς των τιμών, εκφράζει την μεταβλητότητα των δεδομένων απαλλαγμένη από την επίδραση της μέσης τιμής.
- Ένα δείγμα θα χαρακτηρίζεται ομοιογενές, αν η τιμή του δείκτη CV δεν ξεπερνά το 10%.
- Βοηθά στη σύγκριση ομάδων τιμών που είτε εκφράζονται σε διαφορετικές μονάδες μέτρησης είτε εκφράζονται μεν στην ίδια μονάδα μέτρησης αλλά έχουν σημαντικά διαφορετικές μέσες τιμές.
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Μέτρα Μεταβλητότητας (συνέχεια) :
Αρ. Μέθοδοι - Ποσοτικές Μετ.
- Συνοπτικά παίρνω μερικά από τα προηγούμενα περιγραφικά στατιστικά στοιχεία με την συνάρτηση summary() είτε για μία μεταβλητή είτε για ολόκληρο το data frame.
Παράδειγμα:
> summary(cars$speed)
Min. 1st Qu. Median Mean 3rd Qu. Max.
4.0 12.0 15.0 15.4 19.0 25.0
> summary(cars)
speed dist
Min. : 4.0 Min. : 2.00
1st Qu.:12.0 1st Qu.: 26.00
Median :15.0 Median : 36.00
Mean :15.4 Mean : 42.98
3rd Qu.:19.0 3rd Qu.: 56.00
Max. :25.0 Max. :120.00
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(1)
- Ας θυμηθούμε ότι έχουμε δύο κατηγορικές μεταβλητές την Sex και τη Letter_Final_mark στο data frame z
> str(z)
'data.frame': 47 obs. of 8 variables:
$ ID_number : chr "mm12023" "mm12038" "mm12054" "mm12554" ...
$ Sex : Factor w/ 2 levels "F","M": 2 2 2 1 1 1 1 1 2 1 ...
$ Course_total_% : num 65.8 77.67 86.75 3.33 84.13 ...
$ Technical_English: num 2 2 2 0 2 2 1.8 2 2 2 ...
$ EAP : int 1 0 0 0 1 0 0 0 0 0 ...
$ Exam : num 4 3.6 2.5 2.5 6.6 3.9 1.3 1 3.5 4.6 ...
$ Final_mark : int 7 6 2 2 10 6 2 1 6 7 ...
$ Letter_Final_mark: Ord.factor w/ 4 levels "D"<"C"<"B"<"A": 3 2 1 1 4 2 1 1 2 3 ...
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(2)
- Συχνότητα τιμής μιας μεταβλητής: Ο αριθμός των εμφανίσεων της τιμής στο σύνολο τιμών μιας μεταβλητής.
Παράδειγμα:
> table(z$Sex)
F M
19 28
> table(z$Letter_)
D C B A
16 11 15 3
> z$Letter
[1] B C D D A C D D C B B D D <NA> D B C
[18] B B D C B D D D <NA> A B D D D B C C
[35] D C C B A B B B D C B B C
Levels: D < C < B < A
Παρατηρήστε ότι η table() αγνοεί τα ΝΑ. Για παράδειγμα η μεταβλητή Letter έχει 2 NA τα οποία δεν υπoλογίζονται στην table(z$Letter). Οι συχνότητες δίνουν άθροισμα 45 και όχι 47.
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(3)
- Η συχνότητα έχει νόημα και για διακριτές ποσοτικές μεταβλητές.
Παράδειγμα:
> table(cars$speed)
4 7 8 9 10 11 12 13 14 15 16 17 18 19 20 22 23 24 25
2 2 1 1 3 2 4 4 4 3 2 3 4 3 5 1 1 4 1
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(4)
- Σχετική συχνότητα τιμής μιας μεταβλητής : είναι ο λόγος της συχνότητας προς το μέγεθος του δείγματος
Παράδειγμα:
> prop.table(table(z$Sex))
F M
0.4042553 0.5957447
> prop.table(table(z$L))
D C B A
0.35555556 0.24444444 0.33333333 0.06666667
Παρατηρήστε ότι η prop.table() δίνει τις σχετικές συχνότητες και παίρνει σαν όρισμα πίνακα
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(5)
- Πίνακας συνάφειας (contigency table) : πίνακας που δείχνει την κατανομή συχνοτήτων για δύο κατηγορικές μεταβλητές (σχέση μεταξύ τους)
Παράδειγμα:
> ctable<-table(z$Letter,z$Sex)
> ctable
F M
D 7 9
C 3 8
B 5 10
A 3 0
Παρατηρήστε ότι για παράδειγμα από το σύνολο αυτών που πήραν D (16 άτομα) 7 ήταν γυναίκες και 9 άντρες
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(6)
- Τις συχνότητες μόνο της πρώτης μεταβλητής Letter_Final_mark του πίνακα συνάφειας ctable (συχνότητες γραμμών) τις παίρνουμε χρησιμοποιώντας την margin.table(<πίνακας συνάφειας>,1) :
> margin.table(ctable,1)
D C B A
16 11 15 3
> table(z$L)
D C B A
16 11 15 3
Παρατηρήστε ότι το ίδιο αποτέλεσμα έχουμε αν δεν χρησιμοποιήσουμε τον πίνακα συνάφειας ctable αλλά πάρουμε τις συχνότητες της μεταβλητής Letter_Final_mark κατευθείαν μέσω της table().
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(7)
- Οι περιθώριες συχνότητες της πρώτης μεταβλητής Letter_Final_mark του πίνακα συνάφειας ctable (συχνότητες γραμμών) είναι το άθροισμα συχνοτήτων κάθε γραμμής του πίνακα συνάφειας.
> c1<-cbind(ctable, margin.table(ctable,1))
> c1
F M
D 7 9 16
C 3 8 11
B 5 10 15
A 3 0 3
Παρατηρήστε ότι ενώσαμε σε έναν πίνακα c1 τον πίνακα συνάφειας με τον πίνακα των περιθώριων συχνοτήτων για την πρώτη μεταβλητή (γραμμές).
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(8)
- Τις συχνότητες μόνο της δεύτερης μεταβλητής Sex του πίνακα συνάφειας ctable (συχνότητες στηλών) τις παίρνουμε χρησιμοποιώντας την margin.table(<πίνακας συνάφειας>,2) :
> margin.table(ctable,2)
F M
18 27
> table(z$Sex)
F M
19 28
Παρατηρήστε ότι με την margin.table(ctable,2) δεν υπολογίζονται οι παρατηρήσεις που περιέχουν ΝΑ για αυτό έχουμε διαφορετικό αποτέλεσμα χρησιμοποιώντας κατευθείαν την table(z$Sex)
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(9)
- Οι περιθώριες συχνότητες της δεύτερης μεταβλητής Sex του πίνακα συνάφειας ctable (συχνότητες στηλών) είναι το άθροισμα συχνοτήτων κάθε στήλης του πίνακα συνάφειας.
> c2<-rbind(ctable,margin.table(ctable,2))
> c2
F M
D 7 9
C 3 8
B 5 10
A 3 0
18 27
Παρατηρήστε ότι ενώσαμε σε έναν πίνακα c2 τον πίνακα συνάφειας με τον πίνακα των περιθώριων συχνοτήτων για την δεύτερη μεταβλητή (στήλες).
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(10)
- Πίνακας συνάφειας (contigency table) σχετικών συχνοτήτων (Σχετικές συχνότητες κελιών)
Παράδειγμα:
> prop.table(ctable)
F M
D 0.15555556 0.20000000
C 0.06666667 0.17777778
B 0.11111111 0.22222222
A 0.06666667 0.00000000
Παρατηρήστε ότι από τον πίνακα αυτό μπορούμε να πάρουμε τα ποσοστά επί του συνόλου. Για παράδειγμα από το σύνολο όλων των φοιτητών 15% ήταν γυναίκες που πήραν D (Το ποσοστό όλων των φοιτητών που πήραν D είναι 35%).
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(9)
- Τις σχετικές συχνότητες γραμμών ενός πίνακα συνάφειας τις παίρνουμε με την prop.table(<πίνακας συνάφειας>,1) :
> prop.table(ctable,1)
F M
D 0.4375000 0.5625000
C 0.2727273 0.7272727
B 0.3333333 0.6666667
A 1.0000000 0.0000000
Παρατηρήστε ότι με αυτήν την εντολή παίρνουμε αναλυτικά πως κατανέμεται κάθε τιμή της πρώτης μεταβλητής σε σχέση με τις τιμές της δεύτερης. Για παράδειγμα από όλους αυτούς που πήραν D σαν βαθμό (όχι όλους τους φοιτητές) παίρνουμε τι ποσοστό από αυτούς ήταν άντρες και τι γυναίκες.
Αρ. Μέθοδοι - Κατηγορικές Μεταβλητές(12)
- Τις σχετικές συχνότητες στηλών ενός πίνακα συνάφειας τις παίρνουμε με την prop.table(<πίνακας συνάφειας>,2) :
> prop.table(ctable,2)
F M
D 0.3888889 0.3333333
C 0.1666667 0.2962963
B 0.2777778 0.3703704
A 0.1666667 0.0000000
Παρατηρήστε ότι με αυτήν την εντολή παίρνουμε αναλυτικά πως κατανέμεται κάθε τιμή της δεύτερης μεταβλητής σε σχέση με τις τιμές της πρώτης. Για παράδειγμα από όλες τις γυναίκες τι ποσοστό πήρε Α, τι πήρε Β κοκ.
Γραφικές Μέθοδοι στην R(1)
- Ένα από τα μεγάλα πλεονεκτήματα της R είναι οι υψηλού επιπέδου δυνατότητες της στα γραφικά. Αυτός είναι ένας σημαντικός λόγος επιλογής της R από τους επιστήμονες για ανάλυση δεδομένων.
- Αντίθετα με άλλα προγράμματα όπως το Excel και το SPSS τα γραφήματα δημιουργούνται γράφοντας κώδικα και όχι μέσω παραθύρων με απλά διαδοχικά κλικ. Αρχικά αυτό φοβίζει αλλά μετά την πρώτη μύηση αντιλαμβάνεται κανείς τα πλεονεκτήματα:
- Τα γραφικά είναι εύκολα επαναχρησιμοποιήσιμα.
- Μπορούν να γίνουν εύκολα αλλαγές ή να αναπαραχθούν εύκολα τα ίδια γραφικά.
Γραφικές Μέθοδοι στην R(2)
- Το γραφικό πακέτο που περιέχεται by default στην βασική έκδοση της R επιτρέπει τη δημιουργία πολύ καλών γραφημάτων.
- Παραδείγματα από πιο γνωστά γραφικά πακέτα που προστίθενται επιπλέον του βασικού πακέτου είναι τα :
- ggplot2
- ggvis και
- lattice
(δημιουργούν απεικονίσεις με διαφορετικό τρόπο ή απεικονίζουν δεδομένα πολύ εξειδικευμένων επιστημονικών πεδίων).
Γραφ. Μέθοδοι - Ποσοτικές μεταβλητές
- Ιστόγραμμα: Δείχνει οπτικά την κατανομή της μεταβλητής. H συνάρτηση hist() στην R δίνει το ιστόγραμμα ποσοτικής μεταβλητής:
- Ομαδοποιούνται οι τιμές της μεταβλητής σε κλάσεις
- Σχηματίζονται ορθογώνια που το καθένα έχει βάση το εύρος της κλάσης και ύψος την συχνότητα των παρατηρήσεων στην συγκεκριμένη κλάση
Γραφ. Μέθοδοι - Ποσοτικές μετ.
> hist(cars$speed)
![hist(cars$speed)]()
Γραφ. Μέθοδοι - Ποσοτικές μετ.
- Παράδειγμα 2: Μπορούμε να ορίσουμε εμείς πόσες κλάσεις θα σχηματιστούν για να έχουμε περισσότερη λεπτομέρεια.
> hist(cars$s, breaks=10)
![hist(cars$speed_breaks)]() Παρατηρήστε ότι ζητήσαμε το ιστόγραμμα να έχει 10 ενδιάμεσες τιμές (breaks)
Παρατηρήστε ότι ζητήσαμε το ιστόγραμμα να έχει 10 ενδιάμεσες τιμές (breaks)
Γραφ. Μέθοδοι - Ποσοτικές μετ.
- Παράδειγμα 3: Μπορούμε να ορίσουμε το ιστόγραμμα να είναι ιστόγραμμα σχετικών συχνοτήτων.
> hist(cars$s, breaks=10, freq=F)
![hist_sxetikes_syxnotites.png]() Παρατηρήστε ότι θέσαμε freq=FALSE οπότε το ιστόγραμμα παριστά σχετικές συχνότητες και επομένως όλη η επιφάνεια του ισούται με 1. Το ίδιο θα παίρναμε αν δίναμε:
Παρατηρήστε ότι θέσαμε freq=FALSE οπότε το ιστόγραμμα παριστά σχετικές συχνότητες και επομένως όλη η επιφάνεια του ισούται με 1. Το ίδιο θα παίρναμε αν δίναμε:> hist(cars$s, breaks=10, prob=T)
Γραφ. Μέθοδοι- Ποσοτικές μετ.
- Θηκόγραμμα : Δείχνει τα κυριότερα χαρακτηριστικά μιας κατανομής :
- την διάμεσο,
- το ορθογώνιο με άκρα το 1ο και 3ο τεταρτημόριο που περιέχει το μεγαλύτερο μέρος των παρατηρήσεων και
- τα εξωτερικά σημεία που υπολογίζονται από το 1ο (3ο) τεταρτημόριο αν αφαιρέσουμε (προσθέσουμε) 1.5 φορά το ενδοτεταρτομοριακό εύρος. Οι παρατηρήσεις που βρίσκονται εκτός των εξωτερικών σημείων θεωρούνται ακραίες.
- H συνάρτηση boxplot() στην R δίνει το θηκόγραμμα ποσοτικής μεταβλητής.
Γραφ. Μέθοδοι- Ποσοτικές μετ.
- Το θηκόγραμμα περιγράφει αρκετά καλά μία ομάδα τιμών, δίνοντας ιδιαίτερη έμφαση στη διασπορά τους.
- Δείχνει την ύπαρξη συμμετρίας, αν η οριζόντια μαύρη γραμμή διχοτομεί το ορθογώνιο παραλληλόγραμμο.
- Είναι χρήσιμο στον ευκολότερο εντοπισμό ακραίων τιμών («κύκλοι» έξω από το κατακόρυφο ορθογώνιο παραλληλόγραμμο)
![boxplot]() Η συνάρτηση boxplot() της R δεν κάνει διάκριση by default μεταξύ ακραίων και πολύ ακραίων τιμών (δηλ. έξω από το διάστημα \( (Q_{1}-3*IQR, Q_{3}+3*IQR) \)) .
Η συνάρτηση boxplot() της R δεν κάνει διάκριση by default μεταξύ ακραίων και πολύ ακραίων τιμών (δηλ. έξω από το διάστημα \( (Q_{1}-3*IQR, Q_{3}+3*IQR) \)) .
Γραφ. Μέθοδοι- Ποσοτικές μετ.
> boxplot(cars$speed)
> fivenum(cars$speed)
[1] 4 12 15 19 25
![boxplot(cars$speed)]() Αν διατάξουμε τις παρατηρήσεις της μεταβλητής speed κατά αύξουσα σειρά, στο boxplot με το ορθογώνιο απεικονίζεται το σύνολο των παρατηρήσεων που βρίσκεται μεταξύ του 25% και του 75% των παρατηρήσεων, η οριζόντια γραμμή είναι η διάμεσος δηλ. η μεσαία παρατήρηση. Η fivenum() δίνει τα 5 σημεία του boxplot.
Αν διατάξουμε τις παρατηρήσεις της μεταβλητής speed κατά αύξουσα σειρά, στο boxplot με το ορθογώνιο απεικονίζεται το σύνολο των παρατηρήσεων που βρίσκεται μεταξύ του 25% και του 75% των παρατηρήσεων, η οριζόντια γραμμή είναι η διάμεσος δηλ. η μεσαία παρατήρηση. Η fivenum() δίνει τα 5 σημεία του boxplot.
Γραφ. Μέθοδοι- Ποσοτικές μετ.
- Τα θηκογράμματα χρησιμοποιούνται για να έχουμε μια πρώτη εικόνα της κατανομής των μεταβλητών αλλά και για να συγκρίνουμε δύο δείγματα. Παράδειγμα:
> boxplot(cars$speed, cars$dist, names=c("Speed", "Distance"))
![boxplot(cars$s,cars$dist)]() Έχουμε σε ένα διάγραμμα την κατανομή και των δύο μεταβλητών. Στην προκειμένη περίπτωση δεν μπορούμε να συγκρινούμε τις δύο μεταβλητές γιατί έχουν διαφορετική μονάδα μέτρησης.
Έχουμε σε ένα διάγραμμα την κατανομή και των δύο μεταβλητών. Στην προκειμένη περίπτωση δεν μπορούμε να συγκρινούμε τις δύο μεταβλητές γιατί έχουν διαφορετική μονάδα μέτρησης.
Γραφ. Μέθοδοι- Ποσοτικές μετ.
- Τα θηκογράμματα προσφέρουν άμεσο τρόπο να συγκρίνουμε ανά κατηγορία. Παράδειγμα:
> boxplot(z$F~z$Sex)
![boxplot(z$F~z$Sex)]() Σχεδιάστηκε το boxplot μιας αριθμητικής μεταβλητής (Final_mark) ανά level μιας κατηγορικής μεταβλητής τύπου factor (Sex). Στην προκειμένη περίπτωση μπορεί να γίνει σύγκριση. Το ίδιο αποτέλεσμα θα είχαμε και με το πιο σύνθετο:
Σχεδιάστηκε το boxplot μιας αριθμητικής μεταβλητής (Final_mark) ανά level μιας κατηγορικής μεταβλητής τύπου factor (Sex). Στην προκειμένη περίπτωση μπορεί να γίνει σύγκριση. Το ίδιο αποτέλεσμα θα είχαμε και με το πιο σύνθετο:
> boxplot(z$F[z$Sex=="F"],z$F[z$Sex=="M"], names=c("F", "M"))
Γραφ. Μέθοδοι- Ποσοτικές μετ.
- Παράδειγμα 2: Σύγκριση ύψους ανά κατηγορία φύλου
> boxplot(total$height~total$sex)
![boxplot(total$height~total$sex)]()
Γραφ. Μέθοδοι-Κατηγορικές μεταβλητές
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> barplot(table(z$Letter_Final_mark))
![barplot(table(z$Letter_Final_mark))]()
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> barplot(table(z$Sex))
![barplot(table(z$Sex))]()
Γραφ. Μέθοδοι-Κατηγορικές μετ.
- Τομεόγραμμα:
- Απεικονίζει αναλογικά το ποσοστό που καταλαμβάνει κάθε κατηγορία μιας κατηγορικής μεταβλητής ή και αριθμητικής (με λίγες τιμές).
- Ένας κυκλικός δίσκος διαιρείται σε τομείς, όπου τα εμβαδά των τομέων είναι ανάλογα με τις σχετικές συχνότητες των κατηγοριών της μεταβλητής.
- Στην R σχεδιάζω τομεόγραμμα με την συνάρτηση:
pie(table(μεταβλητή))
Προσοχή, χρειάζεται η μεταβλητή να είναι στην μορφή που δίνει η συνάρτηση table().
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> t<-paste(levels(z$Letter_Final_mark), round(prop.table(table(z$Letter_Final_mark)),2),"%")
> t
[1] "D 0.36 %" "C 0.24 %" "B 0.33 %" "A 0.07 %"
> pie(table(z$Letter_Final_mark), labels=t, col=2:5)
![pie(table(z$Letter))]() Παρατηρήστε ότι δηλώσαμε τα χρώματα που θέλαμε και σαν label την συνένωση του γράμματος της βαθμολογίας, με το αντίστοιχο ποσοστό στρογγυλοποιημένο με δύο δεκαδικά ψηφία και το σύμβολο %.
Παρατηρήστε ότι δηλώσαμε τα χρώματα που θέλαμε και σαν label την συνένωση του γράμματος της βαθμολογίας, με το αντίστοιχο ποσοστό στρογγυλοποιημένο με δύο δεκαδικά ψηφία και το σύμβολο %.
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> pie(table(z$Sex))
![pie(table(z$Sex))]()
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> pie(table(z$F))
![pie(table(z$F))]() Η F (Final_mark) είναι αριθμητική μεταβλητή αλλά με λίγες διαφορετικές τιμές (1-10)
Η F (Final_mark) είναι αριθμητική μεταβλητή αλλά με λίγες διαφορετικές τιμές (1-10)
Γραφ. Μέθοδοι-Κατηγορικές μετ.
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> barplot(table(z$Letter, z$Sex))
![barplot(table(z$Letter, z$Sex))]() Ομαδοποιεί ανά φύλο(Sex) και σε κάθε φύλο δείχνει πως κατανέμεται η βαθμολογία (Letter_Final_mark) με στοιβαγμένατα επίπεδα ξεκινώντας από το D<C<B<A
Ομαδοποιεί ανά φύλο(Sex) και σε κάθε φύλο δείχνει πως κατανέμεται η βαθμολογία (Letter_Final_mark) με στοιβαγμένατα επίπεδα ξεκινώντας από το D<C<B<A
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> barplot(table(z$Letter, z$Sex), legend=levels(z$Letter))
![barplot(table(z$Letter, z$Sex), legend=levels(z$Letter))]() Με την παράμετρο legend εμφανίζουμε λεζάντα που στην προκειμένη περίπτωση μας πληροφορεί για τις κατηγορίες της βαθμολογίας (χρώματα που αντιστοιχούν στις κατηγορίες)
Με την παράμετρο legend εμφανίζουμε λεζάντα που στην προκειμένη περίπτωση μας πληροφορεί για τις κατηγορίες της βαθμολογίας (χρώματα που αντιστοιχούν στις κατηγορίες)
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> barplot(table(z$Letter, z$Sex), legend=levels(z$Letter), beside=T)
![barplot(table(z$Letter, z$Sex), legend=levels(z$Letter), beside=T)]() Η παράμετρος beside=T αντί να στοιβάζει την μεταβλητή Letter, τοποθετεί τα ορθογώνια με τις συχνότητες των κατηγοριών το ένα δίπλα στο άλλο
Η παράμετρος beside=T αντί να στοιβάζει την μεταβλητή Letter, τοποθετεί τα ορθογώνια με τις συχνότητες των κατηγοριών το ένα δίπλα στο άλλο
Γραφ. Μέθοδοι-Κατηγορικές μετ.
> prop.table(table(z$Letter, z$Sex),1)
F M
D 0.4375000 0.5625000
C 0.2727273 0.7272727
B 0.3333333 0.6666667
A 1.0000000 0.0000000
Γραφ. Μέθοδοι-Κατηγορικές μετ.
- Παράδειγμα: Χρησιμοποιώντας το prop.table(,1) παίρνουμε αντίστοιχα τις σχετικές συχνότητες της βαθμολογίας ανά φύλο
> barplot(prop.table(table(z$Letter, z$Sex),1), legend=levels(z$Letter), beside=T)
![barplot(prop.table(table(z$Letter, z$Sex),1), legend=levels(z$Letter), beside=T)]()
Γραφ. Μέθοδοι-Κατηγορικές μετ.
- Παράδειγμα: Χρησιμοποιώντας το prop.table(,2) παίρνουμε αντίστοιχα τις σχετικές συχνότητες των στηλών.
> barplot(prop.table(table(z$Letter, z$Sex),2), legend=levels(z$Letter), beside=T)
![Rplot_barplot_L-S_sthlon]()
Γραφ. Μέθοδοι-Κατηγορικές μετ.
- Αντίστοιχα μπορούμε να πάρουμε με ομαδοποίηση ανά βαθμολογία (Letter):
> table(z$Sex, z$Letter)
D C B A
F 7 3 5 3
M 9 8 10 0
Γραφ. Μέθοδοι-Κατηγορικές μετ.
- Παράδειγμα ομαδοποίησης ανά βαθμολογία όπου σε κάθε βαθμολογία δείχνει πως κατανέμεται η μεταβλητή φύλο(Sex) με στοιβαγμένα επίπεδα:
> barplot(table(z$Sex, z$Letter), legend=levels(z$Sex))
![barplot(table(z$Sex, z$Letter), legend=levels(z$Sex))]()
Γραφ. Μέθοδοι-Κατηγορικές μετ.
- Παράδειγμα ομαδοποίησης ανά βαθμολογία με στοιβαγμένα τα επίπεδα για την μεταβλητή φύλο(Sex) στο πλάι.
> barplot(table(z$Sex, z$Letter), legend=levels(z$Sex), beside=T)
![barplot(table(z$Sex, z$Letter), legend=levels(z$Sex), beside=T)]()
Γραφ. Μέθοδοι-Κατηγορικές μετ.
- Παράδειγμα ομαδοποίησης ανά βαθμολογία σχετικών συχνοτήτων με στοιβαγμένα τα επίπεδα για την μεταβλητή φύλο(Sex) στο πλάι.
> barplot(prop.table(table(z$Sex, z$Letter),1), legend=levels(z$Sex), beside=T)
![barplot(prop.table(table(z$Sex, z$Letter),1), legend=levels(z$Sex), beside=T)]()
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- Η πιο γενική στη χρήση συνάρτηση για γραφικά είναι η plot().
- Με τη plot() σχεδιάζει κανείς διαφορετικά γραφήματα.
- Διαφορετικά inputs --> Διαφορετικά γραφήματα
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- plot(ποσοτική μεταβλητή) --> Indexed plot : Αναπαριστά γραφικά τις τιμές ενός διανύσματος
Παράδειγμα:
> plot(cars$speed)
![plot(cars$speed)]()
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- Παράδειγμα 2:
> plot(z$Final)
![plot(z$Final)]()
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- plot(ποσοτική μεταβλητή, ποσοτική μεταβλητή ) --> Διάγραμμα διασποράς (Scatter plot)
- Διάγραμμα διασποράς: Αναπαριστά τα ζεύγη των παρατηρήσεων δύο ποσοτικών μεταβλητών σε ένα διάνυσμα (βλέπουμε την συσχέτιση τους). Στον άξονα των x η πρώτη μεταβλητή.
Γραφ. Μέθοδοι - Η συνάρτηση plot()
> plot(cars$speed, cars$dist)
![plot(cars$speed, cars$dist)]() Φαίνεται από το γράφημα ότι υπάρχει συσχέτιση. Θα γίνει αναφορά στη συχέτιση παρακάτω.
(Όταν οι ποσοτικές μεταβλητές έχουν πολύ μεγάλους αριθμούς είναι καλύτερα να λογαριθμούμε δηλαδή σχεδιάζουμε το γράφημα των λογαρίθμων των ποσοτικών μεταβητών)
Φαίνεται από το γράφημα ότι υπάρχει συσχέτιση. Θα γίνει αναφορά στη συχέτιση παρακάτω.
(Όταν οι ποσοτικές μεταβλητές έχουν πολύ μεγάλους αριθμούς είναι καλύτερα να λογαριθμούμε δηλαδή σχεδιάζουμε το γράφημα των λογαρίθμων των ποσοτικών μεταβητών)
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- plot(κατηγορική μεταβλητή) --> Ραβδόγραμμα (Barplot)
Παράδειγμα:
> plot(z$Letter)
![plot(z$Letter)]() Παρατηρήστε ότι δίνει το ίδιο αποτέλεσμα δηλ. ραβδόγραμμα (χωρίς να απαιτείται η συνάρτηση table() ) με την
Παρατηρήστε ότι δίνει το ίδιο αποτέλεσμα δηλ. ραβδόγραμμα (χωρίς να απαιτείται η συνάρτηση table() ) με την > barplot(table(z$Letter))
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- plot(κατηγ. μεταβλητή, κατηγ. μεταβλητή) --> Στοιβαγμένο ή ομαδοποιημένο ραβδόγραμμα σχετικών συχνοτήτων για την πρώτη μεταβλητή. Παράδειγμα:
> plot(z$Sex, z$Letter)
|
> barplot(prop.table(table(z$Letter, z$Sex),2))
|
![plot(z$Sex, z$Letter)]() |
![Rplot_barplot_L-S_sxet_syxn_sthlon]() |
Παρατηρήστε ότι είναι όμοια με την barplot(prop.table(table(κατηγορική μετ., κατηγορική μετ.),2)). Στις κατηγορίες της μεταβλητής Sex στοιβάζονται όλες οι κατηγορίες της μεταβλητής Letter (σχετ. συχνότητες στηλών). Επίσης, στην plot() δεν χρειάζεται η συνάρτηση table() και η μεταβλητή του άξονα x είναι η πρώτη σε αντίθεση με την barplot().
Γραφ. Μέθοδοι - Η συνάρτηση plot()
> plot(z$Letter, z$Sex)
![plot(z$Letter, z$Sex)]() Σε κάθε βαθμολογία φαίνεται η αναλογία του κάθε φύλου που πέτυχε την συγκεκριμένη βαθμολογία. Το ίδιο θα παίρναμε αν χρησιμοποιούσαμε την barplot() ως εξής:
Σε κάθε βαθμολογία φαίνεται η αναλογία του κάθε φύλου που πέτυχε την συγκεκριμένη βαθμολογία. Το ίδιο θα παίρναμε αν χρησιμοποιούσαμε την barplot() ως εξής:
> barplot(prop.table(table(z$Sex,z$Letter),2))
Σχετικές συχνότητες στηλών του πίνακα συνάφειας των μεταβλητών Sex και Letter.
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- plot(factor, ποσοτική μεταβλ.) ή plot(ποσοτική μεταβλ. ~ factor) --> Θηκόγραμμα (boxplot). Παράδειγμα:
> plot(z$Sex, z$Exam)
|
> plot(z$Exam ~ z$Sex)
|
![plot(z$Sex,z$Exam)]() |
![plot(z$Exam ~ z$Sex)]() |
Παρατηρήστε ότι η R καταλαβαίνει ότι πρόκειται για μια factor μεταβλητή και μια ποσοτική κι έτσι σχεδιάζει το boxplot των βαθμών στις γραπτές εξετάσεις ανά φύλο. (Πρώτη η factor μεταβλητή και μετά η ποσοτική ή ποσοτική ~ factor)
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- Προσοχή! Αν έβαζα στην plot() πρώτα την ποσοτική μεταβλητή και μετά την factor δεν θα μου έδινε boxplot αλλά scatter plot.
Παράδειγμα:
> plot(z$Exam, z$Sex)
![plot(z$Exam, z$Sex)]() Παρατηρήστε ότι μετατρέπει την factor σε αριθμητική μεταβλητή.
Παρατηρήστε ότι μετατρέπει την factor σε αριθμητική μεταβλητή.
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- Παράδειγμα 2:
> plot(z$Sex, z$Final_mark)
|
> plot(z$Final~z$Sex)
|
![plot(z$Sex, z$Final_mark)]() |
![plot(z$Final~z$Sex)]() |
Boxplot της συνολικής βαθμολογίας ανά φύλο.
Γραφ. Μέθοδοι - Η συνάρτηση plot()
- plot(dataframe με αριθμητικές μεταβλητές) ή pairs(dataframe με αριθμητικές μεταβλητές) ---> Πίνακα από scatter plots για όλες τις μεταβλητές. Παράδειγμα:
> plot(mtcars) # ή
> pairs(mtcars)
![plot(mtcars)]() Επειδή όλες οι μεταβλητές του data frame mtcars είναι αριθμητικές μας δίνει ένα πίνακα με όλα τα διαγράμματα διασποράς των μεταβλητών ανά δύο. Η pairs(mtcars) μας δίνει ακριβώς το ίδιο με το plot(mtcars)
Επειδή όλες οι μεταβλητές του data frame mtcars είναι αριθμητικές μας δίνει ένα πίνακα με όλα τα διαγράμματα διασποράς των μεταβλητών ανά δύο. Η pairs(mtcars) μας δίνει ακριβώς το ίδιο με το plot(mtcars)
Γραφ. Μέθοδοι - Η συνάρτηση plot()
> plot(cars)
![plot(cars)]() Επειδή το data frame cars έχει μόνο δύο αριθμητικές μεταβλητές μας δίνει μόνο το scatter plot των δύο αυτών μεταβλητών
Επειδή το data frame cars έχει μόνο δύο αριθμητικές μεταβλητές μας δίνει μόνο το scatter plot των δύο αυτών μεταβλητών
Γραφ. Μέθοδοι - Η συνάρτηση plot()
> plot(z)
Error in plot.window(...) : need finite 'xlim' values
In addition: Warning messages:
1: In data.matrix(x) : NAs introduced by coercion
2: In min(x) : no non-missing arguments to min; returning Inf
3: In max(x) : no non-missing arguments to max; returning -Inf
4: In min(x) : no non-missing arguments to min; returning Inf
5: In max(x) : no non-missing arguments to max; returning -Inf
> pairs(z)
Error in pairs.default(z) : non-numeric argument to 'pairs'
Μας δίνει error γιατί το data frame z περιέχει μια μεταβλητή τύπου character (η πρώτη). Τις μεταβλητές τύπου factor και logical τις μετατρέπει σε αριθμητικές.
Γραφ. Μέθοδοι - Η συνάρτηση plot()
> plot(z[-1]) # ή
> pairs(z[-1])
![plot(z[-1])]() Αφαιρούμε από το data frame την τύπου character μεταβλητή (είναι η πρώτη) και μας δίνει τον πίνακα με τα scatter plot των υπόλοιπων μεταβλητών.
Αφαιρούμε από το data frame την τύπου character μεταβλητή (είναι η πρώτη) και μας δίνει τον πίνακα με τα scatter plot των υπόλοιπων μεταβλητών.

.png)
.png) Παρατηρήστε ότι ζητήσαμε το ιστόγραμμα να έχει 10 ενδιάμεσες τιμές (breaks)
Παρατηρήστε ότι ζητήσαμε το ιστόγραμμα να έχει 10 ενδιάμεσες τιμές (breaks)
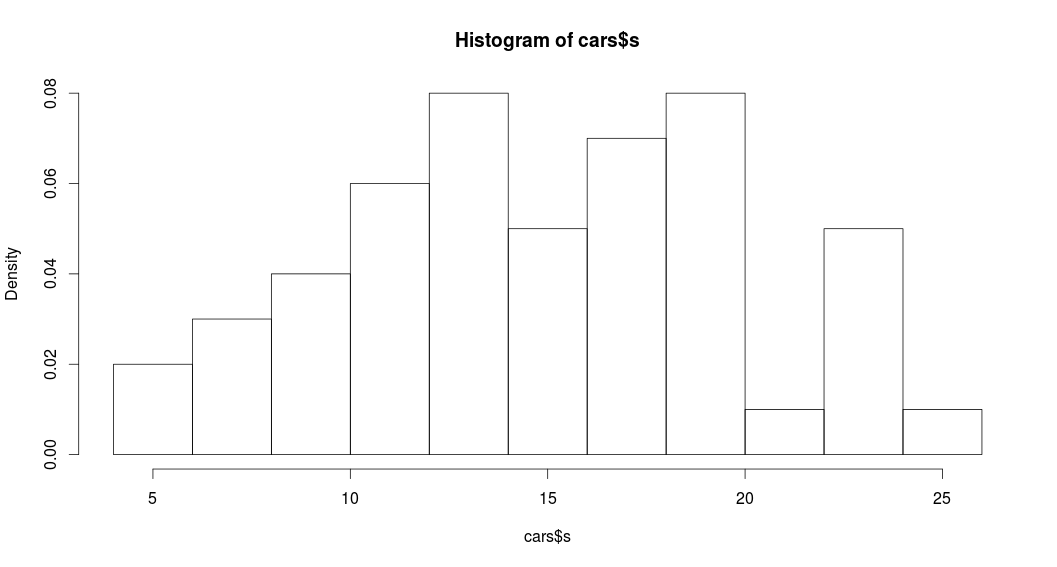 Παρατηρήστε ότι θέσαμε freq=FALSE οπότε το ιστόγραμμα παριστά σχετικές συχνότητες και επομένως όλη η επιφάνεια του ισούται με 1. Το ίδιο θα παίρναμε αν δίναμε:
Παρατηρήστε ότι θέσαμε freq=FALSE οπότε το ιστόγραμμα παριστά σχετικές συχνότητες και επομένως όλη η επιφάνεια του ισούται με 1. Το ίδιο θα παίρναμε αν δίναμε: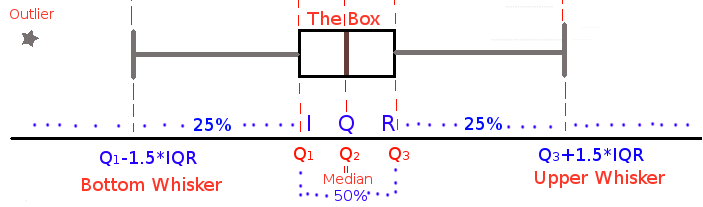 Η συνάρτηση boxplot() της R δεν κάνει διάκριση by default μεταξύ ακραίων και πολύ ακραίων τιμών (δηλ. έξω από το διάστημα \( (Q_{1}-3*IQR, Q_{3}+3*IQR) \)) .
Η συνάρτηση boxplot() της R δεν κάνει διάκριση by default μεταξύ ακραίων και πολύ ακραίων τιμών (δηλ. έξω από το διάστημα \( (Q_{1}-3*IQR, Q_{3}+3*IQR) \)) .
.png) Αν διατάξουμε τις παρατηρήσεις της μεταβλητής speed κατά αύξουσα σειρά, στο boxplot με το ορθογώνιο απεικονίζεται το σύνολο των παρατηρήσεων που βρίσκεται μεταξύ του 25% και του 75% των παρατηρήσεων, η οριζόντια γραμμή είναι η διάμεσος δηλ. η μεσαία παρατήρηση. Η fivenum() δίνει τα 5 σημεία του boxplot.
Αν διατάξουμε τις παρατηρήσεις της μεταβλητής speed κατά αύξουσα σειρά, στο boxplot με το ορθογώνιο απεικονίζεται το σύνολο των παρατηρήσεων που βρίσκεται μεταξύ του 25% και του 75% των παρατηρήσεων, η οριζόντια γραμμή είναι η διάμεσος δηλ. η μεσαία παρατήρηση. Η fivenum() δίνει τα 5 σημεία του boxplot.
.png) Έχουμε σε ένα διάγραμμα την κατανομή και των δύο μεταβλητών. Στην προκειμένη περίπτωση δεν μπορούμε να συγκρινούμε τις δύο μεταβλητές γιατί έχουν διαφορετική μονάδα μέτρησης.
Έχουμε σε ένα διάγραμμα την κατανομή και των δύο μεταβλητών. Στην προκειμένη περίπτωση δεν μπορούμε να συγκρινούμε τις δύο μεταβλητές γιατί έχουν διαφορετική μονάδα μέτρησης.
.png) Σχεδιάστηκε το boxplot μιας αριθμητικής μεταβλητής (Final_mark) ανά level μιας κατηγορικής μεταβλητής τύπου factor (Sex). Στην προκειμένη περίπτωση μπορεί να γίνει σύγκριση. Το ίδιο αποτέλεσμα θα είχαμε και με το πιο σύνθετο:
Σχεδιάστηκε το boxplot μιας αριθμητικής μεταβλητής (Final_mark) ανά level μιας κατηγορικής μεταβλητής τύπου factor (Sex). Στην προκειμένη περίπτωση μπορεί να γίνει σύγκριση. Το ίδιο αποτέλεσμα θα είχαμε και με το πιο σύνθετο:
.png)
).png)
).png)
)_pos.png) Παρατηρήστε ότι δηλώσαμε τα χρώματα που θέλαμε και σαν label την συνένωση του γράμματος της βαθμολογίας, με το αντίστοιχο ποσοστό στρογγυλοποιημένο με δύο δεκαδικά ψηφία και το σύμβολο %.
Παρατηρήστε ότι δηλώσαμε τα χρώματα που θέλαμε και σαν label την συνένωση του γράμματος της βαθμολογίας, με το αντίστοιχο ποσοστό στρογγυλοποιημένο με δύο δεκαδικά ψηφία και το σύμβολο %.
).png)
).png) Η F (Final_mark) είναι αριθμητική μεταβλητή αλλά με λίγες διαφορετικές τιμές (1-10)
Η F (Final_mark) είναι αριθμητική μεταβλητή αλλά με λίγες διαφορετικές τιμές (1-10)
).png) Ομαδοποιεί ανά φύλο(Sex) και σε κάθε φύλο δείχνει πως κατανέμεται η βαθμολογία (Letter_Final_mark) με στοιβαγμένατα επίπεδα ξεκινώντας από το D<C<B<A
Ομαδοποιεί ανά φύλο(Sex) και σε κάθε φύλο δείχνει πως κατανέμεται η βαθμολογία (Letter_Final_mark) με στοιβαγμένατα επίπεδα ξεκινώντας από το D<C<B<A
, legend=levels(z$Letter)).png) Με την παράμετρο legend εμφανίζουμε λεζάντα που στην προκειμένη περίπτωση μας πληροφορεί για τις κατηγορίες της βαθμολογίας (χρώματα που αντιστοιχούν στις κατηγορίες)
Με την παράμετρο legend εμφανίζουμε λεζάντα που στην προκειμένη περίπτωση μας πληροφορεί για τις κατηγορίες της βαθμολογίας (χρώματα που αντιστοιχούν στις κατηγορίες)
, legend=levels(z$Letter), beside=T).png) Η παράμετρος beside=T αντί να στοιβάζει την μεταβλητή Letter, τοποθετεί τα ορθογώνια με τις συχνότητες των κατηγοριών το ένα δίπλα στο άλλο
Η παράμετρος beside=T αντί να στοιβάζει την μεταβλητή Letter, τοποθετεί τα ορθογώνια με τις συχνότητες των κατηγοριών το ένα δίπλα στο άλλο
,1), legend=levels(z$Letter), beside=T).png)
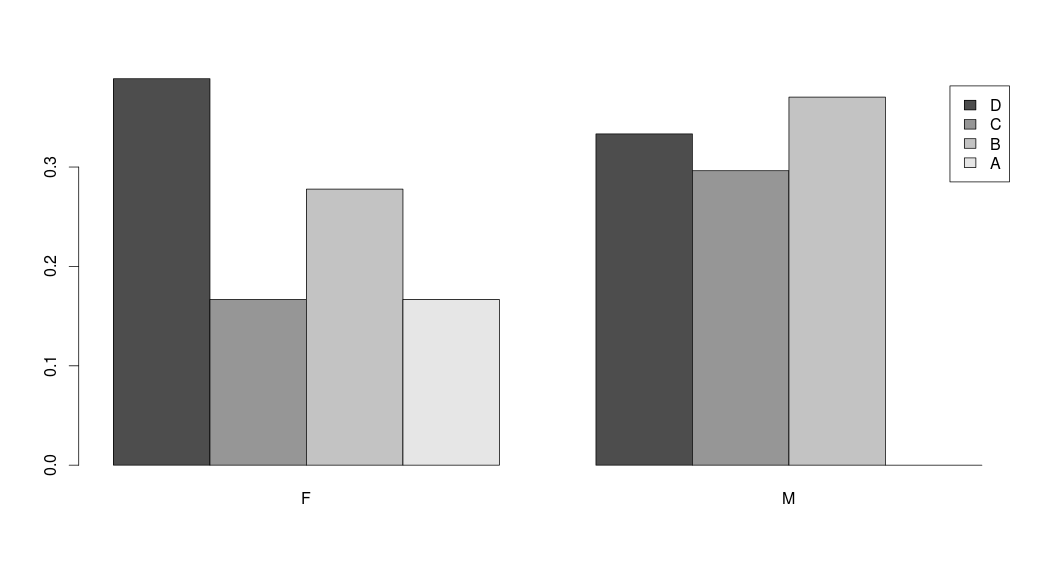
, legend=levels(z$Sex)).png)
, legend=levels(z$Sex), beside=T).png)
,1), legend=levels(z$Sex), beside=T).png)
.png)
.png)
.png) Φαίνεται από το γράφημα ότι υπάρχει συσχέτιση. Θα γίνει αναφορά στη συχέτιση παρακάτω.
(Όταν οι ποσοτικές μεταβλητές έχουν πολύ μεγάλους αριθμούς είναι καλύτερα να λογαριθμούμε δηλαδή σχεδιάζουμε το γράφημα των λογαρίθμων των ποσοτικών μεταβητών)
Φαίνεται από το γράφημα ότι υπάρχει συσχέτιση. Θα γίνει αναφορά στη συχέτιση παρακάτω.
(Όταν οι ποσοτικές μεταβλητές έχουν πολύ μεγάλους αριθμούς είναι καλύτερα να λογαριθμούμε δηλαδή σχεδιάζουμε το γράφημα των λογαρίθμων των ποσοτικών μεταβητών)
.png) Παρατηρήστε ότι δίνει το ίδιο αποτέλεσμα δηλ. ραβδόγραμμα (χωρίς να απαιτείται η συνάρτηση table() ) με την
Παρατηρήστε ότι δίνει το ίδιο αποτέλεσμα δηλ. ραβδόγραμμα (χωρίς να απαιτείται η συνάρτηση table() ) με την .png)
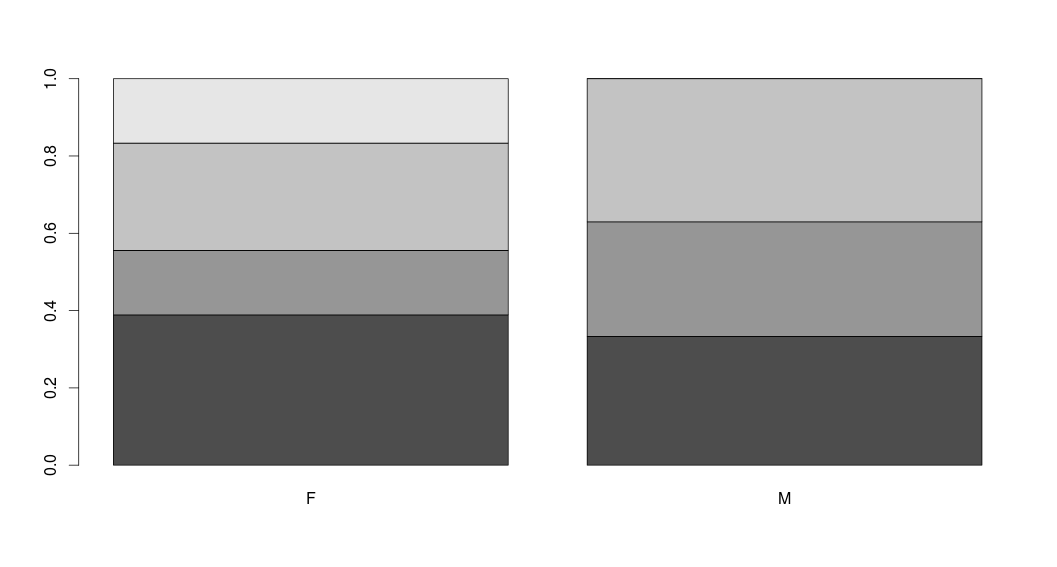
.png) Σε κάθε βαθμολογία φαίνεται η αναλογία του κάθε φύλου που πέτυχε την συγκεκριμένη βαθμολογία. Το ίδιο θα παίρναμε αν χρησιμοποιούσαμε την barplot() ως εξής:
Σε κάθε βαθμολογία φαίνεται η αναλογία του κάθε φύλου που πέτυχε την συγκεκριμένη βαθμολογία. Το ίδιο θα παίρναμε αν χρησιμοποιούσαμε την barplot() ως εξής:
.png)
.png)
.png) Παρατηρήστε ότι μετατρέπει την factor σε αριθμητική μεταβλητή.
Παρατηρήστε ότι μετατρέπει την factor σε αριθμητική μεταβλητή.
.png)
.png)
.png) Επειδή όλες οι μεταβλητές του data frame mtcars είναι αριθμητικές μας δίνει ένα πίνακα με όλα τα διαγράμματα διασποράς των μεταβλητών ανά δύο. Η pairs(mtcars) μας δίνει ακριβώς το ίδιο με το plot(mtcars)
Επειδή όλες οι μεταβλητές του data frame mtcars είναι αριθμητικές μας δίνει ένα πίνακα με όλα τα διαγράμματα διασποράς των μεταβλητών ανά δύο. Η pairs(mtcars) μας δίνει ακριβώς το ίδιο με το plot(mtcars)
.png) Επειδή το data frame cars έχει μόνο δύο αριθμητικές μεταβλητές μας δίνει μόνο το scatter plot των δύο αυτών μεταβλητών
Επειδή το data frame cars έχει μόνο δύο αριθμητικές μεταβλητές μας δίνει μόνο το scatter plot των δύο αυτών μεταβλητών
![plot(z[-1])](photos_paroysiashs/Rplot_pairs_z.png) Αφαιρούμε από το data frame την τύπου character μεταβλητή (είναι η πρώτη) και μας δίνει τον πίνακα με τα scatter plot των υπόλοιπων μεταβλητών.
Αφαιρούμε από το data frame την τύπου character μεταβλητή (είναι η πρώτη) και μας δίνει τον πίνακα με τα scatter plot των υπόλοιπων μεταβλητών.